Cada vez es más fácil localizar cosas o personas específicas entre las cientos de fotos que los usuarios almacenan en sus dispositivos gracias a las nuevas tecnologías de reconocimiento de imágenes.
Con la inteligencia artificial, de la misma forma en la que las personas pueden etiquetar a sus familiares y amigos en los rostros reconocidos por sus dispositivos, las empresas de medios de comunicación ahora pueden etiquetar en su material audiovisual a personajes de la política y la cultura para hacer que las búsquedas de imágenes sean más rápidas.
Sistemas como IBM Watson o Amazon Rekognition cuentan con modelos de visión artificial entrenados para detectar información en imágenes y videos. Algunos de estos modelos también son capaces de identificar texto y diálogos. Estas formas de inteligencia artificial ya están ayudando a periodistas de países desarrollados a ejecutar búsquedas en sus archivos de forma más rápida y eficiente.

El equipo detrás de Image2Text creó un documento con instrucciones para que cualquier sala de redacción pueda hacer uso de la plataforma. (Foto: Captura de pantalla de Image2Text.co)
Pero en el hemisferio sur la historia es diferente. Cuando en 2021 la cadena de medios Grupo Octubre, de Argentina, emprendió el proceso de digitalización de su archivo fotográfico y audiovisual de más de 60 años, recurrió a la inteligencia artificial para identificar y etiquetar a los personajes que aparecían en dichas imágenes para facilitar su posterior búsqueda.
Sin embargo, se toparon con que los algoritmos de las plataformas que estaban usando estaban entrenados para identificar a personalidades anglosajonas y europeas y no reconocían rostros latinoamericanos. Por ejemplo, cuando el sistema leyó una imagen del presidente argentino, Alberto Fernández, lo identificó como el cantante francés Patrick Hernández.
“Las herramientas de este tipo que ya existen en el mercado son herramientas que son buenísimas, que son recontra efectivas y que nosotros usamos, pero que tienen limitaciones, sobre todo en cuestiones de representación”, dijo a LatAm Journalism Review (LJR) Lucila Pinto, periodista que colaboró en el proceso de digitalización del archivo de Grupo Octubre. “Las grandes herramientas son las que tienen Google, IBM y Amazon, servicios cognitivos para describir imágenes. La limitación es que claramente las bases de datos con las cuales fueron y son entrenadas no incluyen la realidad latinoamericana”.
Ante ese obstáculo, el equipo de Grupo Octubre se propuso entrenar un algoritmo de visión computarizada con imágenes de su propio archivo y con bases de datos con contexto latinoamericano. Además, plantearon la idea de crear una herramienta a la que pudiera acceder toda la comunidad periodística de América Latina.
Así fue como surgió Visión Latina, una plataforma que usa inteligencia artificial entrenada específicamente para medios latinoamericanos. El proyecto, desarrollado como parte del Innovation Challenge 2021 de Google News Initiative, ayuda a periodistas y medios latinoamericanos a identificar personajes en su material audiovisual y les permite contribuir al aprendizaje de los algoritmos con su propio material.
“Visión Latina simplemente lo que hace es que le da una herramienta a toda la comunidad para que puedan subir rodaje y reconocer quién es esa gente y transcribirlo”, dijo a LJR Nicolás Russo, product manager de Grupo Octubre, quien agregó que el proyecto tomó un año en su realización, desde enero de 2022 hasta su lanzamiento, en enero de este año.
Por el momento, la plataforma ya está siendo usada por Canal 9 y Página 12, pertenecientes a Grupo Octubre, pero ya está disponible para que otros medios de la región puedan hacer uso de ella.
A mediados de 2022, Pinto y Russo llevaron la idea detrás de Visión Latina a la JournalismAI Fellowship, la iniciativa de JournalismAI, un proyecto de Polis, el think-tank sobre periodismo de la London School of Economics, en la que periodistas y personal técnico de medios de comunicación de todo el mundo trabajan en equipos durante seis meses para desarrollar proyectos de inteligencia artificial que sean de utilidad para el periodismo.
Los representantes de Grupo Octubre hicieron equipo con Sara Campos, de El Surtidor (Paraguay); y con Raymund Sarmiento y Jaemark Tordecilla, de GMA Network (Filipinas), quienes tenían intereses similares sobre el uso de visión computarizada de imágenes para eficientar procesos en sus redacciones.
“GMA tenía la idea de aplicar la inteligencia artificial en video para, por ejemplo, si vuelas un dron por encima de una autopista [...] que el algoritmo se dé cuenta de que hay mucho tráfico”, contó Russo. “Y los chicos de El Surtidor querían aplicar tecnología de inteligencia artificial para que las ilustraciones que ellos hacen sean fácilmente reconocidas por los motores de búsqueda”.
Tomando como base a Visión Latina, el equipo desarrolló un protocolo para que el algoritmo de reconocimiento de imágenes entrenado con contexto latinoamericano pueda compartirse con otras redacciones y que éstas puedan aportar sus bases de datos para hacerlo más “inteligente”.
Fue así como surgió Image2Text, una API (interfaz de programación de aplicaciones, por sus siglas en inglés) que da acceso a un modelo de inteligencia artificial similar al de Visión Latina y que está construido de forma que cada usuario pueda contribuir en su entrenamiento.
De acuerdo con sus creadores, Image2Text busca que más periodistas de distintas regiones, géneros y culturas contribuyan con sus bases de datos a construir un ecosistema de inteligencia artificial más diverso.
“Lo que fuimos a buscar al Fellowship fue investigar maneras de hacer que se pudieran crear bases de datos específicas para entrenar modelos para que funcionen en el contexto latinoamericano del Sur Global”, dijo Pinto. “Cuantas más personas, cuantos más periodistas, cuantas más redacciones en diferentes partes del mundo estén entrenando los modelos, eso va a ayudar a que este tipo de herramientas sean más inclusivas”.

Lucila Pinto, Nicolás Russo y Sara Campos fueron los periodistas latinoamericanos que trabajaron en el desarrollo de Image2Text. (Foto: Captura de pantalla de Image2Text.co)
El sistema funciona de forma similar al reconocimiento facial de aplicaciones como Google Photos: el usuario carga una serie de imágenes o videos a un servicio informático de nube como Amazon Web Services. El algoritmo reconoce los rostros de los personajes y el usuario debe etiquetar cada rostro con el nombre del personaje correspondiente. A partir de entonces, el sistema reconocerá automáticamente a cada personaje en todas las imágenes y videos en los que aparezca.
La idea inicial de crear una plataforma donde cada redacción local entrenara al modelo con su propio material y participara en la creación de una base de datos mayor no fue posible de desarrollar en los seis meses que duró el trabajo en la JournalismAI Fellowship. Sin embargo, el equipo de Image2Text creó un “Starter Pack” diseñado para que cualquier sala de redacción con o sin experiencia en el uso de la inteligencia artificial pueda hacer uso de la API.
Image2Text está disponible en un archivo abierto en GitHub que contiene las instrucciones para ejecutarlo, aunque por el momento su uso todavía requiere de una persona con perfil de programador que conozca Amazon Web Services. El equipo dijo que en una siguiente etapa, buscarán transformar este prototipo en un producto con una interfaz amigable que no requiera grandes conocimientos de programación.
“Lo que hicimos nosotros ahora es una API que necesita que un programador la instale para el que lo quiera usar. En cambio, una vez que convirtamos esa API en una interfaz usable, va a ser más accesible, sin necesidad de tener ese recurso técnico”, explicó Pinto.
El fin último de Image2Text es convertirse en un producto que use inteligencia artificial para identificar imágenes producidas en las salas de redacción, que procese imágenes, videos e infografías y que ayude a categorizarlas, clasificarlas y archivarlas de una manera más eficiente.
Pero otra misión que se planteó el equipo creador desde un inicio fue contribuir a crear un ecosistema de inteligencia artificial más diverso, inclusivo y sin los sesgos raciales, culturales y de lenguaje que presenta hasta hoy. Y en esa misión, los medios locales podrían jugar un papel fundamental.
“La manera de reducir los sesgos es tener a muchas personas, en muchos lugares y en muchas culturas, participando de la producción de estas tecnologías”, dijo Pinto. “Nuestra hipótesis es que cuantos más nodos haya, y entre más distribuidos y representativos, en diferentes culturas y diferentes comunidades estén, finalmente el resultado, el entrenamiento que van a recibir los modelos va a ser más inclusivo que si hay menos nodos, más homogéneos y más centralizados”.
Al terminar la JournalismAI Fellowship, el equipo de Image2Text consiguió una beca de la plataforma de tecnología de almacenamiento y distribución Swarm para continuar el trabajo y llegar a desarrollar un producto cuyo modelo de inteligencia artificial pueda ser entrenado por múltiples redacciones.
Pero además de contribuir a la diversidad y la inclusión en la inteligencia artificial, Image2Text tiene la ventaja que facilita, no solo las búsquedas de imágenes en las redacciones, sino también el trabajo de archivo, sobre todo en medios grandes con archivos históricos que guardan información de varias décadas.
Y para los medios pequeños que no cuentan con un archivista o Media Asset Manager, Image2Text contribuye a evitar que el material producido por el equipo periodístico termine en un archivo personal o en Google Drive y por tanto no pueda ser fácilmente reutilizado en el futuro.
“[Con Image2Text,] lo que estás prometiendo es democratizar mucho más el archivo para todo el resto de la redacción y que se pueda ser muy puntual en las búsquedas”, dijo Russo. “Hay una solución tecnológica que lo que te permite es que la búsqueda en la que antes tardabas tres horas, ahora tardas 10 minutos, y el archivista puede dedicar mucho más su sapiencia de archivista a buscar cosas mucho más profundas que las búsquedas del día a día”.
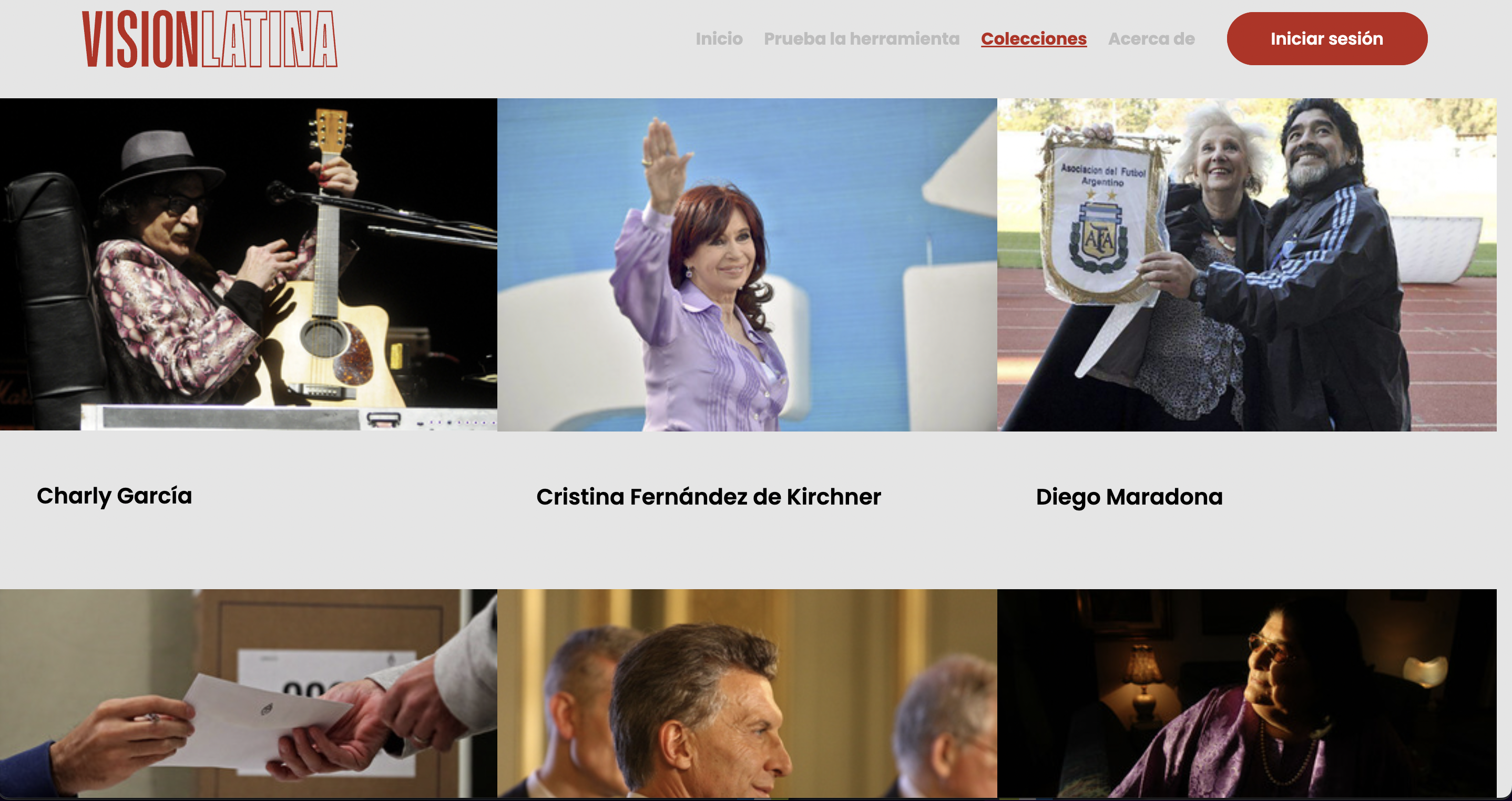
Visión Latina, proyecto desarrollado como parte del Innovation Challenge 2021 de Google News Initiative, usa inteligencia artificial entrenada específicamente para medios latinoamericanos. (Foto: Captura de pantalla de VisionLatina.media)
En el caso de Visión Latina, el proyecto se ha convertido en una nueva fuente de monetización para Grupo Octubre. La plataforma ofrece a medios de la región la posibilidad de cargar sus videos para que el sistema los procese, identifique a los personajes que aparecen y genere la transcripción del audio y descripción a partir de etiquetas generadas de manera automática.
La cadena ofrece además la posibilidad de adquirir material de su archivo ya procesado por la tecnología de Visión Latina y con la metadata de los personajes que ahí aparecen.
“Lo que queremos hacer es disponibilizar más ese rodaje hacia afuera para generar otro ingreso para el canal. Hoy ese trabajo es muy de hormiga”, dijo Russo. “Si te metes en Visión Latina, buscas ahí a cualquier político entre 2018 y 2022, lo encuentras. Cuanto más disponibilizamos el rodaje del canal, más venta va a haber y más plata va a ganar el canal”.


