It is becoming easier and easier to locate specific things or people among the hundreds of photos that users store on their devices thanks to new image recognition technologies.
Thanks to artificial intelligence, in the same way that people can tag their family and friends in the faces recognized by their devices, media companies can now tag political and cultural figures in their audiovisual material to make image searches faster.
Systems such as IBM Watson or Amazon Rekognition have computer vision models trained to detect information in images and videos. Some of these models are also capable of identifying text and dialogue. These forms of artificial intelligence are already helping journalists in developed countries to search their archives faster and more efficiently.

The team behind Image2Text created a document with instructions for any newsroom to make use of the platform. (Photo: Screenshot of Image2Text.co)
But, it’s a different story in the southern hemisphere. When in 2021 the media conglomerate Grupo Octubre, from Argentina, undertook the process of digitizing its photographic and audiovisual archive of more than 60 years, it resorted to artificial intelligence to identify and tag personalities that appeared in those images to facilitate their subsequent search.
However, they found that the algorithms of the platforms they were using were trained to identify Anglo-Saxon and European personalities and did not recognize Latin American faces. For example, when the system read an image of Argentine President Alberto Fernandez, it identified him as French singer Patrick Hernandez.
"The types of tools that already exist in the market are very good tools, they are very effective and we use them, but they have limitations, especially in terms of representation," Lucila Pinto, a journalist who collaborated with the process of digitizing the archive of Grupo Octubre, told LatAm Journalism Review (LJR). “Great tools are those of Google, IBM and Amazon, they offer cognitive services to describe images. The limitation is that, clearly, the databases with which they were and are being trained on, do not include a Latin American reality.”
Faced with this obstacle, the Grupo Octubre team set out to train a computer vision algorithm with images from their own archive and with databases from a Latin American context. In addition, they proposed the idea of creating a tool that could be accessed by the entire Latin American journalistic community.
This is how Visión Latina, a platform that uses artificial intelligence trained specifically for Latin American media, was born. The project, developed as part of the Google News Initiative's Innovation Challenge 2021, helps Latin American journalists and media to identify personalities in their audiovisual footage and allows them to contribute to the learning of algorithms with their own material.
"What Visión Latina simply does is that it provides a tool to the whole community so they can upload footage and recognize who those people are and transcribe it," Nicolás Russo, product manager of Grupo Octubre, told LJR. He added that the project took a year to complete, from January 2022 to its launch in January of this year.
At present, the platform is already being used by Canal 9 and Página 12, which belong to Grupo Octubre. But it is already available to other news outlets in the region to make use of it.
In mid-2022, Pinto and Russo took the idea behind Visión Latina to the JournalismAI Fellowship, an initiative of JournalismAI, a project of Polis, the London School of Economics' journalism think-tank. In this fellowship, journalists and tech staff from news outlets around the world work in teams, for six months, to develop artificial intelligence projects that can be useful to journalism.
Grupo Octubre representatives teamed up with Sara Campos, from El Surtidor (Paraguay); and Raymund Sarmiento and Jaemark Tordecilla, from GMA Network (Philippines), who had similar interests in using computer vision of images to streamline processes in their newsrooms.
"GMA had the idea of applying artificial intelligence to video so, for example, if you fly a drone over a highway [...] that the algorithm realizes that there's a lot of traffic," Russo said. “And the guys from El Surtidor wanted to apply artificial intelligence technology so the illustrations they make are easily recognized by search engines.”
Based on Visión Latina, the team developed a protocol so that the image recognition algorithm trained with a Latin American context can be shared with other newsrooms. They in turn can contribute their own databases to make it “smarter.”
This is how Image2Text was created, an API (application programming interface) that provides access to an artificial intelligence model similar to that of Visión Latina and which is built in such a way that each user can contribute to its training.
According to its creators, Image2Text seeks to get more journalists from different regions, genres and cultures to contribute their databases to build a more diverse artificial intelligence ecosystem.
"What we went after at the Fellowship was to investigate ways to make it possible to create specific databases to train models to work in a Latin American context of the Global South," Pinto said. "The more people, the more journalists, the more newsrooms in different parts of the world that are training the models, that's going to help make these kinds of tools more inclusive."

Lucila Pinto, Nicolás Russo and Sara Campos were the Latin American journalists who worked on the development of Image2Text. (Photo: Screenshot of Image2Text.co)
The system works in a similar way to facial recognition in applications such as Google Photos: the user uploads a series of images or videos to a cloud computing service such as Amazon Web Services. The algorithm recognizes the faces of the personalities and the user must tag each face with the corresponding personality’s name. Thereafter, the system will automatically recognize each personality in all images and videos in which they appear.
During the six-month work period at the JournalismAI Fellowship, it was not possible to develop the initial plan of creating a platform where each local newsroom would train the model with its own material and participate in the creation of a larger database. However, the Image2Text team created a "Starter Pack," which was designed so that any newsroom with or without experience using artificial intelligence can make use of the API.
Image2Text is available in an open file on GitHub that contains the instructions to run it, although for now its use still requires a programmer-type person familiar with Amazon Web Services. The team said that in a next stage, they will seek to transform this prototype into a product with a user-friendly interface that would not require extensive programming knowledge.
"What we created now is an API that requires a programmer to install it for whoever wants to use it. On the other hand, once we convert this API into a usable interface, it will be more accessible, without the need for this technical assistance," Pinto said.
Image2Text's ultimate goal is to become a product that uses artificial intelligence to identify images produced in newsrooms, process images, videos and infographics, and help categorize, classify and archive them more efficiently.
But another mission that the creative team set out to do from the beginning was to help create a more diverse, inclusive artificial intelligence ecosystem without the racial, cultural and language biases it has to date. And in that mission, local media could play a key role.
"The way to reduce bias is to have many people, in many places and in many cultures, participating in the production of these technologies," Pinto said. "Our hypothesis is that the more nodes there are, and the more distributed and representative in different cultures and different communities they are, ultimately the result, the training that the models are going to receive is going to be more inclusive than if there are fewer, more homogeneous, more centralized nodes."
Upon completion of the JournalismAI Fellowship, the Image2Text team won a grant from storage and distribution technology platform Swarm to continue the work and eventually develop a product whose artificial intelligence model can be trained by multiple newsrooms.
But in addition to contributing to diversity and inclusion in artificial intelligence, Image2Text has the advantage of facilitating not only image searches in newsrooms, but also archival work, especially in large media outlets with historical archives that have information stored from several decades.
And for smaller news outlets that do not have an archivist or Media Asset Manager, Image2Text helps to prevent the material produced by the journalistic team from ending up in a personal archive or in Google Drive and therefore not being easily reused in the future.
"[With Image2Text,] what you're promising is that you're democratizing the archive much more for the whole rest of the newsroom and that you can be very timely in your searches," Russo said. "There's a technological solution that allows you to do the search that used to take three hours and now it takes 10 minutes. The archivist can then devote much more of their archival wisdom to looking for things that are much more in-depth than day-to-day searches."
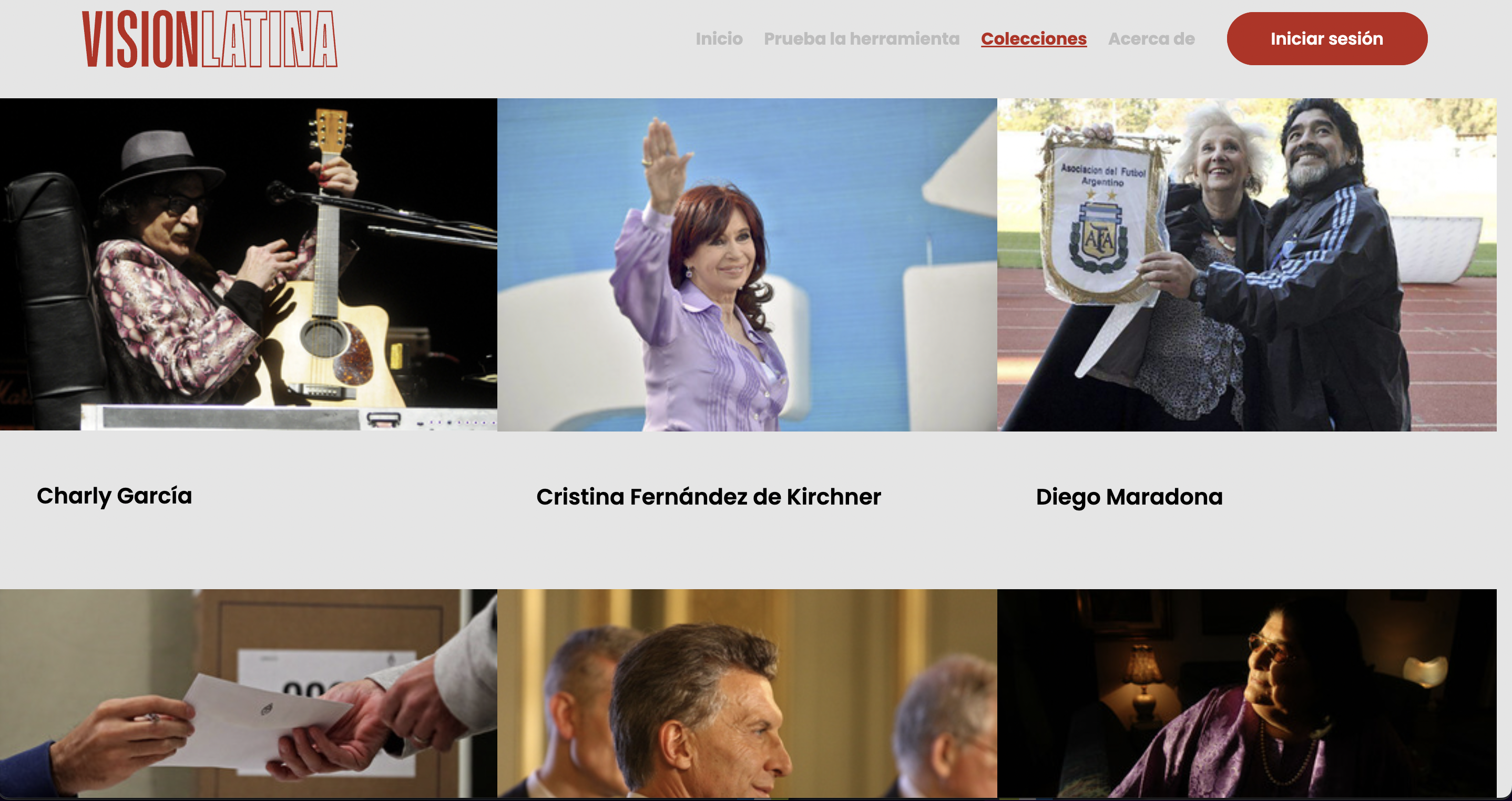
Visión Latina, a project developed as part of the Google News Initiative's Innovation Challenge 2021, uses artificial intelligence trained specifically for Latin American media. (Photo: Screenshot of VisionLatina.media)
In the case of Visión Latina, the project has become a new source of monetization for Grupo Octubre. The platform offers the region's media the possibility of uploading their videos so that the system can process them, identify the personalities that appear and generate the transcription of the audio and description based on automatically generated tags.
The network also offers the possibility of acquiring material from its archive already processed by Visión Latina's technology and with the metadata of personalities appearing in it.
"What we want to do is to make that footage more available to the outside world to generate other income for the network. Today that work is very hard work," said Russo. "If you go to Visión Latina, you look there for any politician between 2018 and 2022, you’ll find him or her. The more we make the channel's filming available, the more sales there are going to be and the more money the network is going to earn."


