Las periodistas de la revista digital feminista AzMina, de Brasil, notaron que mucha de la violencia hacia las mujeres en su país se originaba en redes sociales. Quisieron investigar al respecto y para ello desarrollaron una metodología de monitoreo de violencia en línea.
Bajo esta metodología, desde 2020 AzMina ha publicado una serie de investigaciones de datos, en alianza con organizaciones como InternetLab, Volt Data Lab y INCT.DD, las cuales revelan cómo las mujeres de la política y el periodismo son víctimas de ataques e insultos en redes sociales que intentan deslegitimar su capacidad intelectual para el ejercicio de sus profesiones.
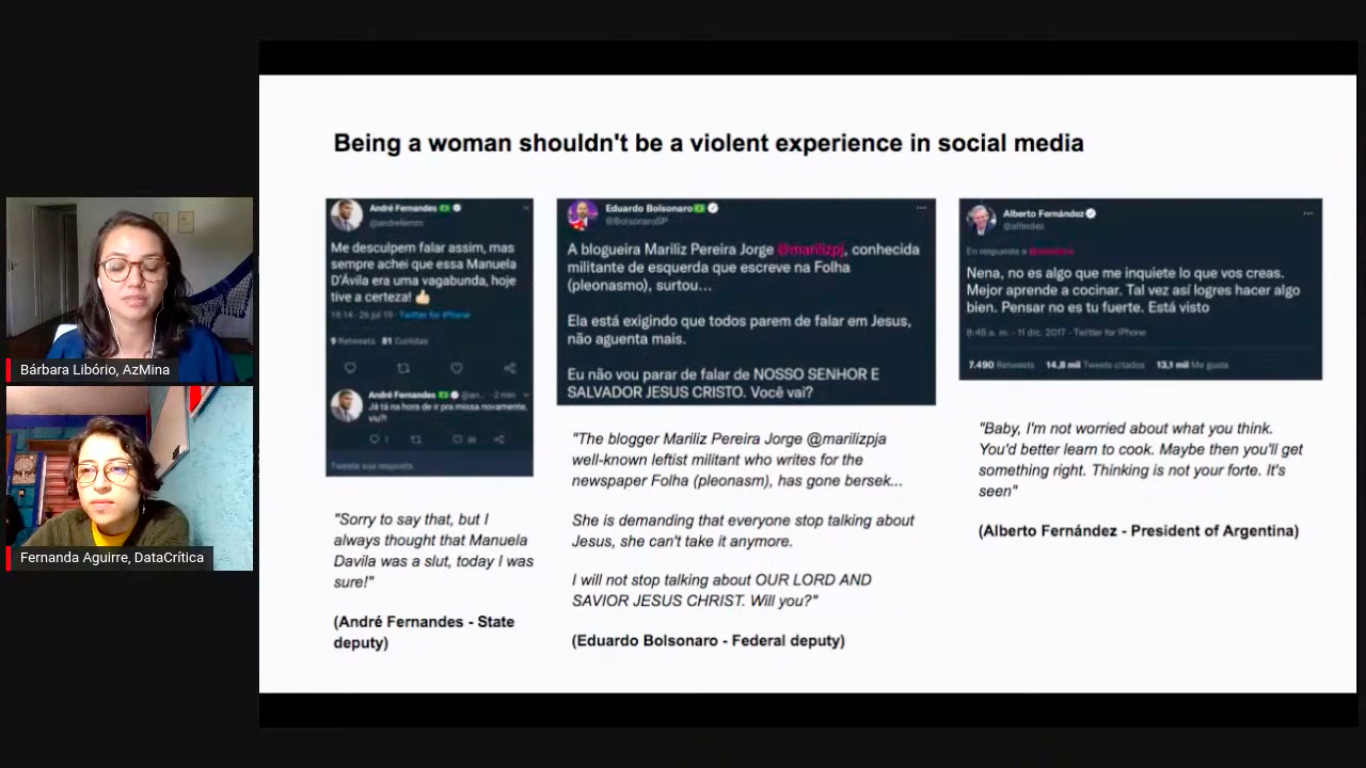
El Monitor de Discurso Político Misógino fue desarrollado como parte del Collab Challenge, una iniciativa de JournalismAI y Google News Initiative. (Foto: Captura de pantalla de transmisión de YouTube)
“Teníamos que leer y analizar tweet por tweet, comentario por comentario”, dijo Bárbara Libório, gerente de periodismo y proyectos de AzMina, a LatAm Journalism Review (LJR). “Tuvimos un trabajo manual y humano muy grande, de leer muchos tweets, muchas publicaciones, muchos comentarios. Pensamos ‘como me gustaría que la inteligencia artificial pudiera hacer eso por nosotros, porque lo haría con mucha más asertividad y mucho más rápido’. Somos un equipo muy pequeñito y teníamos que hacer muchas otras cosas al mismo tiempo, lo cual nos llevaba mucho tiempo y esfuerzo, y pensamos que la inteligencia artificial podría ayudarnos”.
Por ello, cuando Libório y otras dos integrantes del equipo de AzMina fueron aceptadas para participar en el Collab Challenge 2021, la iniciativa global de JournalismAI y Google News Initiative que reúne a medios de todo el mundo para desarrollar innovaciones en periodismo mediante inteligencia artificial, decidieron presentar como proyecto a desarrollar su metodología de monitoreo de violencia en línea contra mujeres, con miras a crear una herramienta que les resultara de utilidad en su cobertura de las próximas elecciones presidenciales de 2022 en Brasil.
“Sabíamos que queríamos seguir con el monitor, pero necesitábamos ayuda tecnológica, no solo manual y humana, por eso pensamos que podría ser una buena idea [...] tener algún aprendizaje que pudiéramos llevar a nuestro equipo y a nuestro proyecto”, dijo Libório. “Pero cuando presentamos nuestra idea, vimos que otras organizaciones también estaban interesadas en una herramienta así, no solo por la cuestión de género y machismo, sino por la cuestión del discurso de odio en general”.
Libório y sus compañeras de AzMina Helena Bertho y Marina Gama Cubas da Silva formaron equipo con Fernanda Aguirre, de Data Crítica (México); Gaby Bouret, de La Nación (Argentina); y José Luis Peñarredonda, de CLIP (Colombia) para desarrollar lo que al final se convertiría en el Monitor de Discurso Político Misógino.
Se trata de una API (interfaz de programación de aplicaciones, por sus siglas en inglés) que, mediante un modelo entrenado de Procesamiento de Lenguaje Natural (PLN), detecta discurso de odio contra mujeres en internet en español y portugués. La herramienta tiene el potencial de automatizar el análisis de publicaciones en línea mediante el aprendizaje automático para que los periodistas puedan enfocarse en tareas más cruciales de sus investigaciones sobre violencia de género.
“Hemos encontrado muchos proyectos que intentan monitorear con inteligencia artificial el discurso de odio, pero no hay tantos que lo hagan alrededor de la misoginia”, dijo Libório. “Para los periodistas creo que el principal problema es el tiempo que nos cuesta, porque es bastante tiempo y esfuerzo que invertimos en leer todas las publicaciones y analizar si son ataques misóginos o no. Si tenemos una inteligencia artificial que haga eso por nosotros con asertividad y escalabilidad, tendríamos muchísimo tiempo para enfocar nuestros esfuerzos en otras cosas, como hacer entrevistas o buscar los perfiles que están ejerciendo los ataques, o hacer investigaciones más profundas, con más tiempo”.
El primer paso para construir el Monitor consistió en actualizar el diccionario de términos misóginos que AzMina había creado para sus proyectos de monitoreo de comentarios misóginos en redes. Esos términos fueron usados para entrenar un modelo de aprendizaje automático de PLN.
Los participantes de Data Crítica, La Nación y CLIP crearon además sus propios diccionarios en español basados en el diccionario de AzMina. Recopilaron términos ofensivos hacia las mujeres en redes sociales y los ordenaron por tipo de ofensas, como insultos por complexión física, raza, ataques al intelecto, ofensas transfóbicas y ataques sexuales, entre otros.
“Pensamos que era algo tan sencillo como traducir el diccionario en portugués y ya está. Pero no era tan fácil como eso. Muchas cosas en español no tenían sentido o no eran misóginas”, explicó Aguirre, analista de datos de Data Crítica, a LJR. “Nos dimos cuenta que al final es una cosa que recae mucho en el contexto y que parece que es muy fácil identificar si un tweet es misógino y la verdad es que a veces no era tan fácil”.
El equipo utilizó el modelo de procesamiento de lenguaje natural BERT (Representaciones de Codificador Bidireccional de Transformadores, por sus siglas en inglés), desarrollado por Google, el cual es capaz de “aprender” las relaciones contextuales entre las palabras de un texto. El equipo seleccionó una muestra de tweets tanto en portugués como en español que incluían las palabras contenidas en los diccionarios y etiquetó manualmente aquellos que podían considerarse misóginos. Después usaron esa muestra para entrenar al modelo a identificar tweets misóginos.
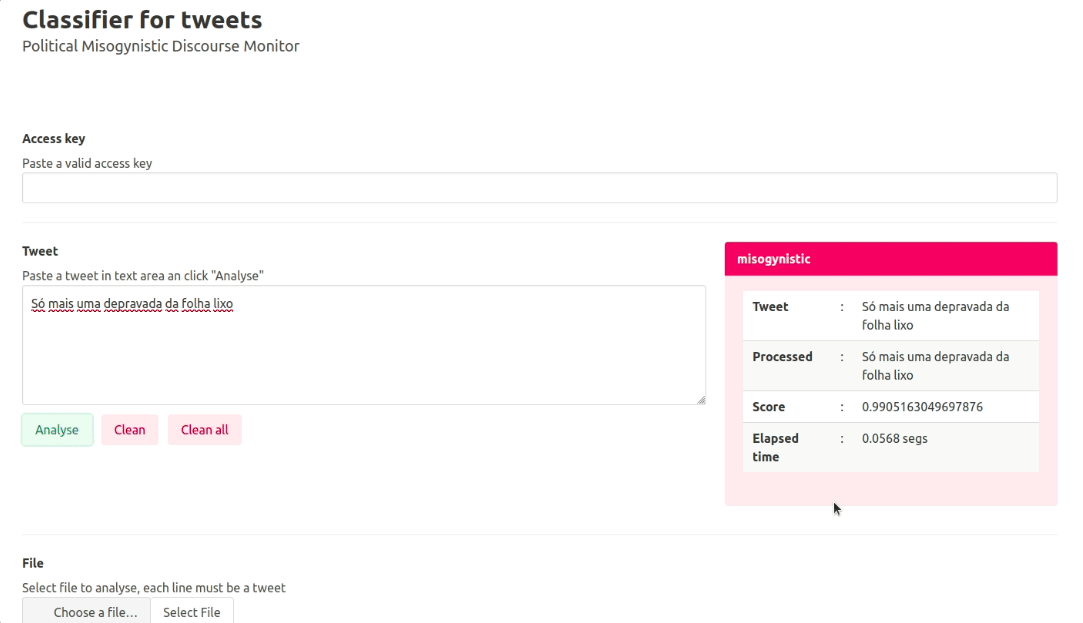
La herramienta tiene el potencial de automatizar el análisis de tweets mediante aprendizaje automático para que los periodistas puedan enfocarse en tareas más cruciales. (Foto: Cortesía)
“En general, todos estos modelos entienden cosas del lenguaje porque fueron alimentados por un montón de texto”, explicó Aguirre. “Tú tomas este modelo y refinas ese conocimiento para que aprenda algo muy específico, que en nuestro caso era ‘tú ya sabes cosas del lenguaje, ahora queremos que aprendas a identificar textos que sean misóginos’. Esto se puede utilizar para un montón de cosas, pero nuestro objetivo era el discurso misógino”.
El equipo contó con el apoyo de Iván Vladimir Meza, investigador experto en cómputo de lenguaje humano de la Facultad de Ingeniería de la Universidad Nacional Autónoma de México (UNAM), para el entrenamiento del modelo BERT y la posterior creación de la API del Monitor.
Luego de hacer un primer entrenamiento, el equipo se encontró con que el modelo detectaba tweets que contenían palabras consideradas misóginas, pero que estaban escritas sin la intención de ofender, lo cual generaba “falsos positivos” de discurso misógino.
Asimismo, los periodistas se dieron cuenta que la cultura y el contexto de cada país influye significativamente en la interpretación del contenido misógino. Por ejemplo, algunos términos que son considerados misóginos en Colombia no lo son en México o Argentina, y viceversa. De modo que el equipo tuvo que ejecutar una doble verificación en el etiquetado de los tweets para asegurarse que eran intencionalmente misóginos.
“Yo etiquetaba los [tweets] de México y luego verificaba los etiquetados por Gaby de Argentina y veía si estaba de acuerdo con lo que ella había etiquetado. Y Gaby verificaba los de José Luis y éste verificaba los míos”, explicó Aguirre. “Si uno no estaba de acuerdo con el etiquetado de otro, ese tweet se salía de la base de datos. Solamente incluimos los etiquetados en los que tanto etiquetador como verificador estuvieran de acuerdo que era misógino”.
También tras el primer entrenamiento, el equipo se dio cuenta que BERT funcionaba con más precisión en español que en portugués, aunque en ninguno de los dos idiomas la efectividad era tan alta como en inglés. Fue entonces que decidieron llevar a cabo un segundo entrenamiento, esta vez con modelos diferentes para cada idioma. Una vez terminada su participación en el Collab Challenge, el equipo decidió realizar un tercer entrenamiento para refinar los resultados en portugués todavía más.
“Tuvimos este reto de que el PLN en inglés es muchísimo mejor, en español funciona bien y en portugués, más o menos… En nuestro entrenamiento, los resultados en español han sido mejores que los resultados en portugués”, dijo Libório. “Yo creo que este tercer entrenamiento va a ayudarnos un poco a aclarar las ideas”.
A lo largo del proceso, tanto Libório como el resto de los integrantes se han dado cuenta que monitorear discurso es una tarea prácticamente interminable por la evolución natural del lenguaje humano y por los cambios en el contexto social. Pese a que el equipo de AzMina ya tenía diccionarios de términos misóginos de sus trabajos anteriores, el actualizarlos con nuevas formas de agresiones a mujeres en redes significó prácticamente hacer todo el trabajo de nuevo.
“El lenguaje es una cosa muy viva, así que es un trabajo que nunca se acaba. Siempre que vas a trabajar con el lenguaje tienes que pensar que es algo muy vivo que debe ser actualizado siempre”, dijo Libório. “Eso da un poco de ansiedad, porque tiene esa sensación de que el trabajo nunca está acabado y es algo importante que debes tener en mente cuando vas a estimar tus esfuerzos”.
A raíz de su participación en el Collab Challenge, los periodistas de AzMina, Data Crítica, La Nación y CLIP aprendieron que todavía es muy complicado para un medio latinoamericano crear innovación en inteligencia artificial por sí solo, no solamente por la falta de recursos económicos, sino también por la falta de conocimientos técnicos. Igualmente, aprendieron que la colaboración entre periodistas y con profesionales expertos en tecnología es crucial para desarrollar una herramienta como el Monitor de Discurso Político Misógino.
Además de la alianza con el ingeniero de la UNAM, los periodistas contaron con mentoría técnica de Jeremy Gilbert, Joe Germuska y Scott Bradley del Knight Lab de la Northwestern University, en Estados Unidos, organización que sirvió como aliado regional y punto de contacto entre el equipo y los organizadores del Collab Challenge.
“Como periodistas de datos, sabemos lo que necesitamos y tenemos estas ideas pero no tenemos el conocimiento técnico. Es por eso que nosotros hicimos la alianza con Iván (Meza)”, dijo Libório. “Tuvimos que buscar una alianza con alguien que no era de periodismo, porque creo que hay ese gap que como periodistas sabemos lo que nos gustaría hacer, cómo debería ser la herramienta, lo que debe tener, pero no tenemos los conocimientos técnicos para realizarla”.

AzMina planea continuar aplicando su metodología de monitoreo en temas de violencia de género en línea. (Foto: tomada del Instagram de AzMina)
La alianza con Meza también significó un apoyo financiero indirecto. Al ser investigador del Instituto de Investigaciones en Matemáticas Aplicadas y Sistemas (IIMAS) de la UNAM, el ingeniero tuvo la posibilidad de usar uno de los servidores de la institución para alojar la API del Monitor y mantenerlo ahí hasta por dos años, mientras los medios detrás del proyecto encuentran la forma de financiar un hosting por sí mismos.
“Muchas veces la academia tiene los medios para poder sustentar este tipo de proyectos”, dijo Aguirre. “Probablemente si no hubiéramos hecho esta colaboración con Iván, no sé cómo hubiéramos solventado todo esto, pagar el hospedaje, el servidor… Por eso creo que la colaboración puede ser clave para medios pequeños como es nuestro caso. Sin la colaboración con otros medios y con Iván y su laboratorio, no hubiéramos podido hacer lo que hicimos o nos hubiera resultado bastante caro y no lo hubiéramos podido mantener”.
Aunque la herramienta ya es funcional y puede ser utilizada, el plan del equipo es optimizar al máximo su funcionamiento antes de aplicarlo en investigaciones periodísticas. Una vez que alcance un nivel de precisión ideal, planean ponerla a disposición de otros medios como herramienta de código abierto.
“Nos gustaría que esta API fuera abierta para que otras redacciones y otras personas pudieran probarla o poner ahí el texto de un tweet, de una publicación y tener una respuesta”, dijo Libório. “Estamos buscando becas y oportunidades que quizá podríamos lograr para tener más financiamiento para el proyecto”.
Las ventajas de un modelo de inteligencia artificial como el Monitor de Discurso Político Misógino es que puede ser entrenado para detectar otros tipos de discurso y en otras plataformas de texto escrito además de Twitter. Aunque por el momento, Data Crítica le va gran potencial para extender su aplicación para combatir la violencia contra mujeres periodistas en México.
“En un principio, imaginábamos continuar el trabajo de AzMina sobre violencia contra mujeres en la política y extenderlo para ver lo que estaba pasando con las mujeres en la política en México o en Colombia”, dijo Aguirre. “Pero después yo he imaginado mucho cómo esta herramienta puede ser aplicada -específicamente en México- en violencia contra mujeres periodistas. Es interesante esta herramienta aplicada al periodismo para poder entender esta oleada de violencia contra mujeres, y cómo podríamos utilizarla para ayudar a esas periodistas que están siendo atacadas”.
Por su parte, AzMina espera poder aplicar el Monitor de Discurso Político Misógino en su cobertura de las elecciones de Brasil en 2022, además de continuar aplicando su metodología de monitoreo en otros temas de género, como en su proyecto “Elas no Congresso” (Ellas en el Congreso), nominado al Premio Gabo 2020 en la categoría Innovación, el cual monitorea proyectos de ley o iniciativas que tienen que ver con derechos de las mujeres en el Congreso de Brasil a partir de datos públicos.
“Las personas tienen que entender que es muy bonito ver una inteligencia artificial en funcionamiento, pero que hay muchísimo trabajo humano antes de eso”, dijo Libório. “A todos les gusta ver la inteligencia artificial funcionando, pero a nadie le gusta etiquetar tweets, publicaciones, leer miles de textos. Todo eso es esencial, porque si no hay trabajo humano para que los datos sean efectivos, para que estemos seguros de lo que estamos haciendo, la inteligencia artificial no va a funcionar. Es muy importante que ese trabajo también sea valorado”.


