The journalists of the feminist digital magazine AzMina, from Brazil, noticed that much of the violence against women in their country originated in social media. They wanted to investigate the issue and developed a methodology for monitoring online violence.
Under this methodology, since 2020, AzMina has published a series of data investigations in partnership with organizations such as InternetLab, Volt Data Lab and INCT.DD. That research shows how women in politics and journalism are victims of attacks and insults on social media that attempt to delegitimize their intellectual capacity to practice their professions.
The Misogynist Political Discourse Monitor was developed as part of the Collab Challenge, an initiative of JournalismAI and Google News Initiative. (Photo: YouTube live streaming screenshot)
"We had to read and analyze tweet by tweet, comment by comment," Bárbara Libório, AzMina's journalism and project manager, told LatAm Journalism Review (LJR). "We had a lot of manual and human work, reading many tweets, many posts, and many comments. We thought 'how I wish artificial intelligence could do that for us, because it would do it much more assertively and much faster.' We're a very small team and we had a lot of other things to do at the same time, which took a lot of time and effort, so we thought artificial intelligence could help us."
So when Libório and two other members of the AzMina team were accepted to participate in the Collab Challenge 2021, the global initiative of JournalismAI and Google News Initiative that brings together media from around the world to develop innovations in journalism through artificial intelligence (AI), they decided to present as a project to be developed their methodology for monitoring online violence against women, with a view to creating a tool that would be useful in their coverage of the upcoming 2022 presidential elections in Brazil.
"We knew we wanted to continue with the monitor, but we needed tech help, not just manual and human help, so we thought it might be a good idea [...] to learn something we could take back to our team and our project," Libório said. "But when we presented our idea, we saw that other organizations were also interested in such a tool, not only because of the gender and machismo issue, but because of the issue of hate speech in general."
Libório and AzMina colleagues Helena Bertho and Marina Gama Cubas da Silva teamed up with Fernanda Aguirre of Data Crítica (Mexico); Gaby Bouret of La Nación (Argentina); and José Luis Peñarredonda of CLIP (Colombia) to develop what would eventually become the Political Misogynist Discourse Monitor (PMDM).
It is an API (application programming interface) that, through a trained Natural Language Processing (NLP) model, detects hate speech against women on the Internet in Spanish and Portuguese. The tool has the potential to automate the analysis of online publications through machine learning, so that journalists can focus on more crucial tasks in their investigations of gender-based violence.
"We have found many projects that try to monitor hate speech with AI, but not so many related to misogyny," Libório said. “For journalists, I think the main problem is the cost in time, because it's quite a lot of time and effort we invest in reading all the posts and analyzing whether they are misogynistic attacks or not. If we had artificial intelligence that did that for us with assertiveness and scalability, we’d have plenty of time to focus our efforts on other things, such as doing interviews or looking for profiles perpetrating the attacks, or doing deeper research, with more time.”
The first step in building the Monitor was to update the dictionary of misogynistic terms that AzMina had created for its projects to monitor misogynistic comments in social media. These words were used to train a NLP machine learning model.
Participants from Data Crítica, La Nación and CLIP also created their own Spanish dictionaries based on AzMina's dictionary. They collected offensive terms towards women in social media and sorted them by type of offense, such as insults based on physical complexion, race, attacks on intellect, transphobic offenses, and sexual attacks, among others.
"We thought it’d be something as simple as translating our dictionary into Portuguese and that’d be it. But it wasn't as easy as that. A lot of things in Spanish didn't make sense or weren't misogynistic," Aguirre, a data analyst at Data Crítica, told LJR. "We realized that, in the end, it's something that depends a lot on context. It seemed very easy to identify whether a tweet was misogynistic, but the truth is that sometimes it’s not so easy."
The team used the BERT (Bidirectional Encoder Representations of Transformers) natural language processing model, developed by Google, which is able to "learn" the contextual relationships between words in a text. The team selected a sample of tweets in both Portuguese and Spanish that included words contained in the dictionaries and manually labeled those that could be considered misogynistic. They then used that sample to train the model to identify tweets that were misogynistic.
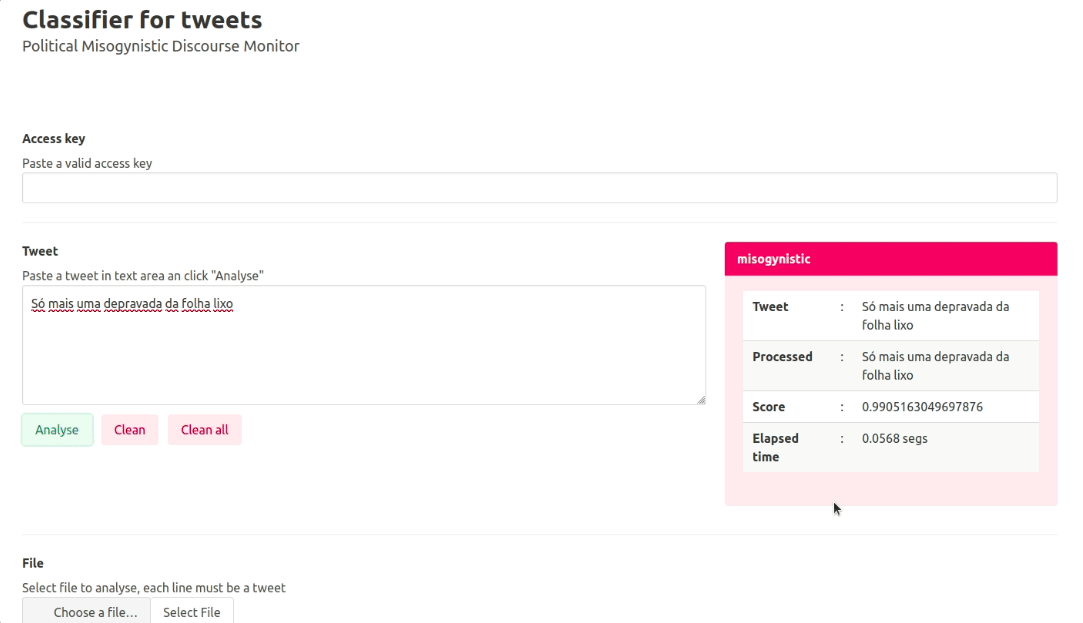
The tool has the potential to automate tweet analysis through machine learning, so journalists can focus on more crucial tasks. (Photo: Courtesy)
"In general, all these models understand things about language because they were fed a lot of text," Aguirre explained. "You take this model and refine that knowledge so that it learns something very specific, which in our case was 'you already know things about language, now we want you to learn how to identify texts that are misogynistic.' This can be used for a lot of things, but our target was misogynistic speech."
The team had the support of Iván Vladimir Meza, an expert researcher in human language computation at the School of Engineering at the National Autonomous University of Mexico (UNAM), for the training of the BERT model and the subsequent creation of the Monitor API.
After initial training, the team found that the model detected tweets that contained words considered misogynistic, but that were written without an intent to offend, which generated "false positives" of misogynistic speech.
The journalists also realized that the culture and context of each country significantly influence the interpretation of misogynistic content. For example, some terms that are considered misogynistic in Colombia are not in Mexico or Argentina, and vice versa. So the team had to double-check the labeling of the tweets to make sure they were intentionally misogynistic.
"I would tag the [tweets] from Mexico and then check the ones tagged by Gaby from Argentina and see if I agreed with what she had tagged. And Gaby would check José Luis' and José Luis would check mine," Aguirre explained. "If one of us did not agree with the tagging of another, that tweet was out of the database. We only included tags in which both tagger and verifier agreed that it was misogynistic."
Also after the first training, the team realized that BERT worked more accurately in Spanish than in Portuguese, although in neither language was the effectiveness as high as in English. It was then that they decided to carry out a second training, this time with different models for each language. Once their participation in the Collab Challenge was over, the team decided to conduct a third training to refine the results in Portuguese even further.
"We faced this challenge that the NLP in English is much, much better, in Spanish it works well and in Portuguese, so, so... During our training, the results in Spanish have been better than the results in Portuguese," Libório said. "I think this third training is going to help us clarify the ideas a bit."
Throughout the process, both Libório and the rest of the team realized that monitoring discourse is a practically endless task due to the natural evolution of human language and changes in the social context. Although the AzMina team already had dictionaries of misogynist terms from their previous work, updating them with new forms of aggression against women in social media practically meant doing the work all over again.
"Language is a living thing in the extreme, so it's a job that never ends. Whenever you work with language, you have to realize that it's very much alive and needs to be constantly updated," Libório said. "That’s a bit anxiety-provoking, because you get the feeling that the work is never done. It's an important consideration when estimating how much of an effort you’re going to put into it."
As a result of their participation in the Collab Challenge, journalists from AzMina, Data Crítica, La Nación, and CLIP learned that it is still very complicated for a Latin American news outlet to spur innovation in AI on its own, not only because of lack of economic resources, but also because of lack of technical knowledge. They also learned that collaborating with other journalists and with technology-savvy professionals is crucial to developing a tool such as the Political Misogynist Discourse Monitor.
In addition to their partnership with the UNAM engineer, the journalists received technical mentoring from Jeremy Gilbert, Joe Germuska and Scott Bradley of the Knight Lab at Northwestern University in the United States, an organization that served as a regional ally and point of contact between the team and the Collab Challenge organizers.
"As data journalists, we know what we need and we have these ideas, but we don't have the technical know-how. That 's why we partnered with Iván (Meza)," Libório said. "We had to look for a partnership with someone from outside journalism, because I think there is this gap that as journalists we know what we would like to do, what the tool should look like, what it should contain, but we don't have the tech knowledge to make it happen."

AzMina plans to continue applying its monitoring methodology to gender-based violence online. (Photo: AzMina's Instagram)
The alliance with Meza also meant indirect financial support. As a researcher at UNAM's Institute for Research in Applied Mathematics and Systems (IIMAS), the engineer was able to use one of the institution's servers to host the Monitor API and keep it there for up to two years, while the news outlets behind the project found a way to finance hosting on their own.
"Oftentimes, academia has the means to sustain this type of project," Aguirre said. "Probably, if we hadn't collaborated with Iván, I don't know how we would’ve paid for all this, for the hosting, the server... That's why I think collaboration can be key for small media, as in our case. Without collaborating with other media and with Iván and his lab, we would’ve not been able to do what we did or it would’ve been quite expensive and we would’ve not been able to maintain it."
Although the tool is already functional and can be used, the team's plan is to optimize it as much as possible before applying it to investigative journalism. Once it reaches an ideal level of accuracy, they plan to make it available to other media as an open source tool.
"We would like this API to be open so other newsrooms and other people can test it or insert the text of a tweet, of a post and get a response," Libório said. "We are looking for grants and opportunities to perhaps have more funding for the project."
The advantages of an artificial intelligence model like the Political Misogynistic Speech Monitor is that it can be trained to detect many other types of speech and on other written text platforms besides Twitter. For now, though, Data Crítica sees great potential to extend its application to combat violence against women journalists in Mexico.
"At first, we imagined continuing AzMina's work on violence against women in politics and extending it to see what was happening with women in politics in Mexico or Colombia," Aguirre said. "But then I’ve thought a lot about how this tool could be applied - specifically in Mexico - to violence against women journalists. It is interesting to consider this tool applied to journalism to be able to understand this wave of violence against women, and how we could use it to help those journalists who are being attacked."
For its part, AzMina hopes to apply the Political Misogynist Discourse Monitor in its coverage of Brazil's elections in 2022. In addition, they want to continue applying this monitoring methodology to other gender issues, such as in their project "Elas no Congresso" (Women in Congress). This project was nominated for the Gabo 2020 Award in the Innovation category, and monitors bills or initiatives that have to do with women's rights in the Brazilian Congress based on public data.
"People have to understand that while it's very nice to see artificial intelligence at work, there is a lot of human work put in before that," Libório said. "Everybody likes to see AI working, but nobody likes to tag tweets, posts, or read thousands of texts. All of that is essential, because if there is no human work to make the data effective, so that we are certain of what we are doing, AI is not going to work. It's very important for that work to also be valued."


