É cada vez mais fácil localizar coisas ou pessoas específicas nas centenas de fotos que os usuários armazenam em seus dispositivos, graças às novas tecnologias de reconhecimento de imagem.
Graças à inteligência artificial, da mesma forma que as pessoas podem marcar familiares e amigos nos rostos reconhecidos por seus dispositivos, as empresas de meios de comunicação já podem marcar figuras da política e da cultura em seu material audiovisual para tornar as buscas de imagem mais rápidas.
Sistemas como IBM Watson ou Amazon Rekognition possuem modelos de visão artificial treinados para detectar informações em imagens e vídeos. Alguns desses modelos também são capazes de identificar textos e diálogos. Essas formas de inteligência artificial já estão ajudando os jornalistas de países desenvolvidos a fazerem buscas em seus arquivos de forma mais rápida e eficiente.

A equipe por trás da Image2Text criou um documento com instruções para que qualquer redação possa fazer uso da plataforma. (Foto: Captura de tela de Image2Text.co)
Mas no Hemisfério Sul a história é diferente. Em 2021, quando iniciou o processo de digitalização de seu arquivo fotográfico e audiovisual de mais de 60 anos, o grupo de mídia Grupo Octubre, da Argentina, recorreu à inteligência artificial para identificar e rotular as pessoas que apareciam nessas imagens para facilitar buscas posteriores.
Mas eles descobriram que os algoritmos das plataformas que estavam usando tinham sido treinados para identificar personalidades anglo-saxônicas e europeias e não reconheciam rostos latino-americanos. Por exemplo, quando o sistema leu uma imagem do presidente argentino Alberto Fernández, ele o identificou como o cantor francês Patrick Hernández.
“As ferramentas desse tipo que já existem no mercado são ferramentas que são muito boas, que são eficazes e que nós usamos, mas que têm limitações, principalmente em questões de representação”, disse Lucila Pinto, jornalista que colaborou no processo de digitalização do acervo do Grupo Octubre, à LatAm Journalism Review (LJR). “As grandes ferramentas são as do Google, da IBM e da Amazon, são serviços cognitivos para descrever imagens. A limitação é que claramente os bancos de dados com os quais elas foram e são treinadas não incluem a realidade latino-americana.”
Diante desse obstáculo, a equipe do Grupo Octubre decidiu treinar um algoritmo de visão computadorizada com imagens de seu próprio arquivo e com bancos de dados com um contexto latino-americano. Além disso, levantaram a ideia de criar uma ferramenta que pudesse ser acessada por toda a comunidade jornalística da América Latina.
Foi assim que surgiu a Visión Latina, uma plataforma que utiliza inteligência artificial treinada especificamente para meios latino-americanos. O projeto, desenvolvido como parte do Innovation Challenge 2021 da Google News Initiative, ajuda jornalistas e meios de comunicação latino-americanos a identificarem pessoas em seu material audiovisual e permite que contribuam para o aprendizado de algoritmos com material próprio.
"O que Visión Latina faz é simplesmente dar a toda a comunidade uma ferramenta para que possam fazer upload de imagens, reconhecer essas pessoas e transcrever essa informação", disse Nicolás Russo, gerente de produto do Grupo Octubre, à LJR, acrescentando que o projeto foi realizado em um ano, de janeiro de 2022 até seu lançamento, em janeiro deste ano.
Atualmente, a plataforma é utilizada pelo Canal 9 e pelo jornal Página 12, do Grupo Octubre, mas já está disponível para que outros veículos da região possam usá-la.
Em meados de 2022, Pinto e Russo apresentaram a ideia da Visión Latina à JournalismAI Fellowship, uma iniciativa do JournalismAI, projeto do Polis, o think-tank de jornalismo da London School of Economics, no qual jornalistas e técnicos de meios de comunicação de todo o mundo trabalham em equipe durante seis meses para desenvolver projetos de inteligência artificial para o jornalismo.
Os representantes do Grupo Octubre formaram uma equipe com Sara Campos, do El Surtidor (Paraguai), e Raymund Sarmiento e Jaemark Tordecilla, da GMA Network (Filipinas), que tinham interesses semelhantes para usar a visão computadorizada de imagens para agilizar os processos em suas redações.
“A GMA queria aplicar a inteligência artificial em vídeo para, por exemplo, se você enviar um drone para sobrevoar uma estrada […] o algoritmo consiga perceber que tem muito trânsito”, disse Russo. “E o pessoal do El Surtidor queria aplicar a tecnologia de inteligência artificial para que as ilustrações que eles fazem fossem facilmente reconhecidas pelos mecanismos de busca.”
Tomando como base a Visión Latina, a equipe desenvolveu um protocolo para que o algoritmo de reconhecimento de imagem treinado com o contexto latino-americano possa ser compartilhado com outras redações, que poderão contribuir com suas bases de dados para torná-lo mais “inteligente”.
Foi assim que surgiu Image2Text, uma API (interface de programação de aplicativos) que dá acesso a um modelo de inteligência artificial parecido com o da Visión Latina, construído de forma que cada usuário possa contribuir com seu treinamento.
De acordo com seus criadores, a Image2Text está procurando mais jornalistas de diferentes regiões, gêneros e culturas para contribuir com seus bancos de dados para construir um ecossistema de inteligência artificial mais diversificado.
“Nós buscamos a Fellowship para investigar formas de tornar possível a criação de bancos de dados específicos para treinar modelos para trabalhar no contexto latino-americano do Sul Global”, disse Pinto. “Quanto mais pessoas, quanto mais jornalistas, quanto mais redações em diferentes partes do mundo estiverem treinando os modelos, mais isso nos ajudará a tornar esse tipo de ferramenta mais inclusiva.”

Lucila Pinto, Nicolás Russo e Sara Campos foram os jornalistas latino-americanos que trabalharam no desenvolvimento de Image2Text. (Foto: Captura de tela de Image2Text.co)
O sistema funciona de forma semelhante ao do reconhecimento facial de aplicativos como o Google Fotos: o usuário envia uma série de imagens ou vídeos para um serviço de computação em nuvem, como o Amazon Web Services, o algoritmo reconhece os rostos das pessoas e o usuário rotula cada rosto com o nome correspondente. A partir daí, o sistema reconhecerá automaticamente a pessoa em todas as imagens e vídeos em que aparecer.
Os seis meses de trabalho no JournalismAI Fellowship não foram suficientes para desenvolver a ideia inicial de criar uma plataforma onde cada redação local treinasse o modelo com seu próprio material e participasse da criação de um banco de dados maior. Mas a equipe da Image2Text criou um “Starter Pack” pensado para que qualquer redação, com ou sem experiência no uso de inteligência artificial, pudesse usar a API.
A Image2Text está disponível em um arquivo aberto no GitHub, que também contém as instruções para executá-la. Por enquanto, ela só pode ser utilizada por uma pessoa com perfil de programador que conheça a Amazon Web Services. De acordo com a equipe, em uma próxima etapa esse protótipo será transformado em um produto com uma interface amigável que não exija grandes conhecimentos de programação.
“O que fizemos agora é uma API que precisa de um programador para instalar para quem quiser usar. Mas assim que transformarmos essa API em uma interface utilizável, ela será mais acessível, e não necessitará desse recurso técnico”, explica Pinto.
O objetivo final da Image2Text é se tornar um produto que usa inteligência artificial para identificar imagens produzidas em redações, processar imagens, vídeos e infográficos e ajudar a categorizá-los, classificá-los e arquivá-los com mais eficiência.
Desde o início do projeto, a equipe criativa estabeleceu a missão de ajudar a criar um ecossistema de inteligência artificial mais diversificado e inclusivo, sem o viés racial, cultural e linguístico que apresenta atualmente. Nessa missão, meios locais poderiam desempenhar um papel fundamental.
“A maneira de reduzir o viés é ter muitas pessoas, em muitos lugares e em muitas culturas, participando da produção dessas tecnologias”, disse Pinto. “Nossa hipótese é que quanto mais pontos de intersecção houver, e quanto mais distribuídos e representativos eles forem, em diferentes culturas e diferentes comunidades, o resultado, o treinamento que os modelos receberão será mais inclusivo do que se houver menos pontos de intersecção, mais homogêneos e mais centralizados.”
Após o encerramento da JournalismAI Fellowship, a equipe da Image2Text recebeu uma bolsa da plataforma de tecnologia de armazenamento e distribuição Swarm para continuar o trabalho e desenvolver um produto cujo modelo de inteligência artificial possa ser treinado em várias redações.
Além de contribuir para a diversidade e a inclusão na inteligência artificial, a Image2Text tem a vantagem de facilitar não só as buscas de imagens nas redações, mas também o trabalho de arquivamento, principalmente em grandes mídias com arquivos históricos que guardam informações de várias décadas.
Para pequenos meios de comunicação que não possuem um arquivista ou Media Asset Manager, a Image2Text ajuda a evitar que o material produzido pela equipe de notícias acabe em um arquivo pessoal ou no Google Drive, não sendo, portanto, facilmente reutilizável no futuro.
“[Com a Image2Text] o que você está prometendo é democratizar muito mais o arquivo para toda a redação e ser muito pontual nas buscas”, disse Russo. “Existe uma solução tecnológica que permite fazer uma busca que antes levava três horas e que agora leva 10 minutos, e o arquivista pode dedicar muito mais de sua sabedoria de arquivista para buscar coisas muito mais profundas do que as buscas do dia a dia.”
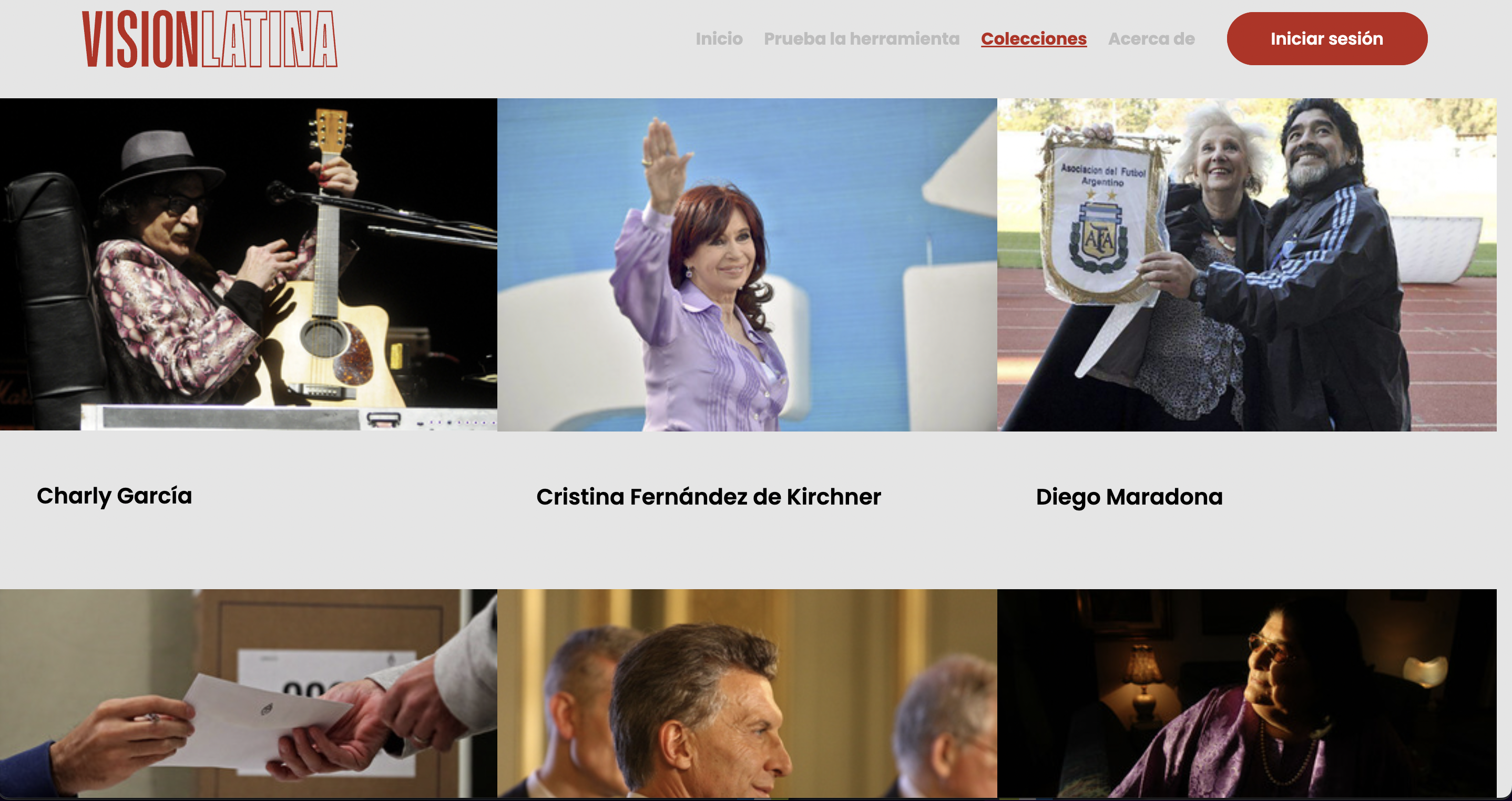
Visión Latina, projeto desenvolvido como parte do Innovation Challenge 2021 da Google News Initiative, usa inteligência artificial treinada especificamente para meios latino-americanos. (Foto: Captura de tela de VisionLatina.media)
No caso da Visión Latina, o projeto se tornou uma nova fonte de monetização para o Grupo Octubre. A plataforma oferece aos meios de comunicação da região a possibilidade de enviar seus vídeos para que o sistema possa processá-los, identificar as pessoas que aparecem e gerar a transcrição e a descrição do áudio com base em tags geradas automaticamente.
A rede também oferece a possibilidade de adquirir material de seu arquivo já processado pela tecnologia da Visión Latina e com os metadados das pessoas que ali aparecem.
“O que queremos é disponibilizar mais os vídeos para outros, para gerar outra receita para o canal. Hoje esse trabalho é bem de formiguinha”, disse Russo. “Se procurar qualquer político entre 2018 e 2022 na Visão Latina, você encontrará. Quanto mais disponibilizarmos os vídeos do canal, mais nós vamos vender e mais dinheiro o canal vai ganhar.”


